【译】Claude Code凭什么这么好用?(以及如何在你的AI智能体中复现这种魔力)
Claude Code是我迄今用过的最令人愉悦的AI智能体/工作流。它不仅让进行有针对性的代码编辑或编写一次性小工具这类“随性编程”变得不再烦人,使用Claude Code甚至让我感到快乐。它有足够的自主性来做一些有趣的事情,同时又不会像其他一些工具那样,带来令人不适的失控感。当然,大部分繁重的工作是由新的Claude 4模型完成的(尤其是其交错思维能力)。但我发现,即便使用相同的底层模型,Claude Code在客观上用起来也比Cursor或Github Copilot的智能体要舒服得多!它究竟凭什么这么好用?如果你在读这篇文章时也正点头赞同,我将尝试给出一些答案。
注意: 这不是一篇泄露Claude Code架构的博文(网上已经有一些不错的了)。这篇博文旨在成为一份构建优秀LLM(大语言模型)智能体的指南,它基于我过去几个月使用和琢磨Claude Code的个人经验(以及我们拦截并分析的所有日志)。你可以在附录部分找到提示词和工具。本文约2000词,请坐稳了!如果你想快速了解要点,**“长话短说”**部分是个不错的起点。
(图片描述:你可以清楚地看到Claude Code的不同更新。)
Claude Code (CC) 的使用体验非常棒,因为它就是好用。CC的打造基于一个根本性的理解:LLM擅长什么,又不擅长什么。它的提示词和工具弥补了模型的“愚蠢之处”,并帮助其在核心优势区大放异彩。其控制循环极易理解,调试起来也毫不费力。
我们MinusX在CC一发布就开始使用它了。为了探其究竟,Sreejith编写了一个日志记录器,可以拦截并记录它发出的每一个网络请求。以下分析源于我过去几个月的大量使用。本文试图回答这个问题——“是什么让Claude Code如此出色,以及你如何在自己的基于聊天的LLM智能体中提供类似的体验?” 我们已经将其中大部分理念融入了MinusX,我也很期待看到你们也这样做!
(图片描述:Edit(编辑)是最常用的工具,其次是Read(读取)和ToDoWrite(写入待办事项)。)
如何构建一个类似Claude Code的智能体:长话短说(TL;DR)
如果说本文只有一个核心要点,那就是——保持简单,傻瓜(Keep Things Simple, Dummy)。LLM的调试和评估已经够糟糕了。你引入的任何额外复杂性(多智能体、智能体交接或复杂的RAG搜索算法)只会让调试难度增加10倍。如果这样一个脆弱的系统侥幸能跑起来,你日后也会因为害怕对其进行大刀阔斧的改动而畏手畏脚。所以,把所有东西都放在一个文件里,避免过度的样板代码和脚手架,并且至少彻底推倒重来几次 :)
以下是从Claude Code中提炼出的,可以在你自己的系统中实现的主要经验:
- 控制循环(Control Loop)
- 1.1 保持一个主循环(最多一个分支)和一份消息历史。
- 1.2 大量使用一个更小的模型来处理各种事情。无时无刻,所有地方!
- 提示词(Prompts)
- 2.1 使用
claude.md模式来协作并记住用户偏好。 - 2.2 使用特殊的XML标签、Markdown和大量示例。
- 2.1 使用
- 工具(Tools)
- 3.1 LLM搜索 >>> 基于RAG的搜索。
- 3.2 如何设计好工具?(高级工具 vs 低级工具)。
- 3.3 让你的智能体管理自己的待办事项列表。
- 可控性(Steerability)
- 4.1 语气和风格。
- 4.2 “请注意,这很重要” 不幸地仍然是业界顶尖水平(State of the Art)。
- 4.3 编写算法,并附上启发式规则和示例。
Claude Code在每个节点都选择了架构上的简洁性——一个主循环、简单的搜索、简单的待办事项列表等。抵制过度设计的冲动,为模型构建良好的约束框架,然后让它自由发挥! 这难道又是端到端自动驾驶的老路吗?惨痛教训(Bitter lesson)真是学不够啊?
1. 控制循环设计
1.1 保持一个主循环
可调试性 >>> 复杂的、手动调优的、多智能体、lang-chain-graph-node式的乱七八糟的混合体。
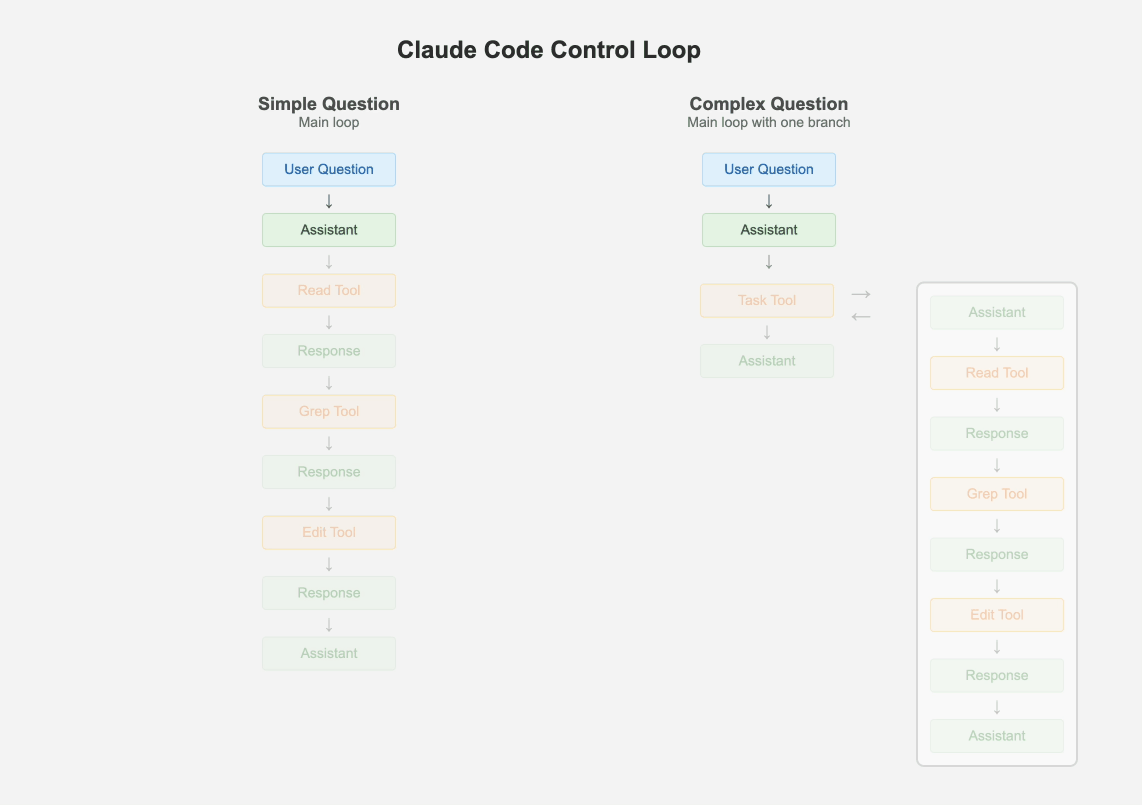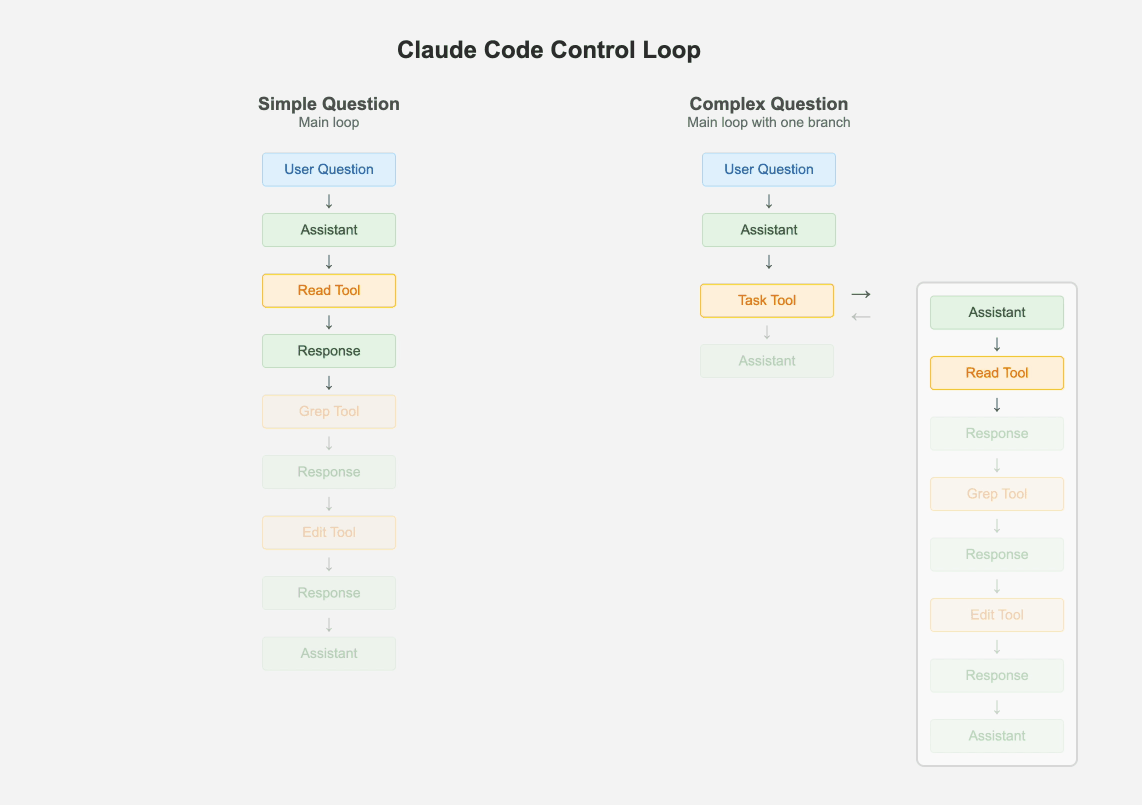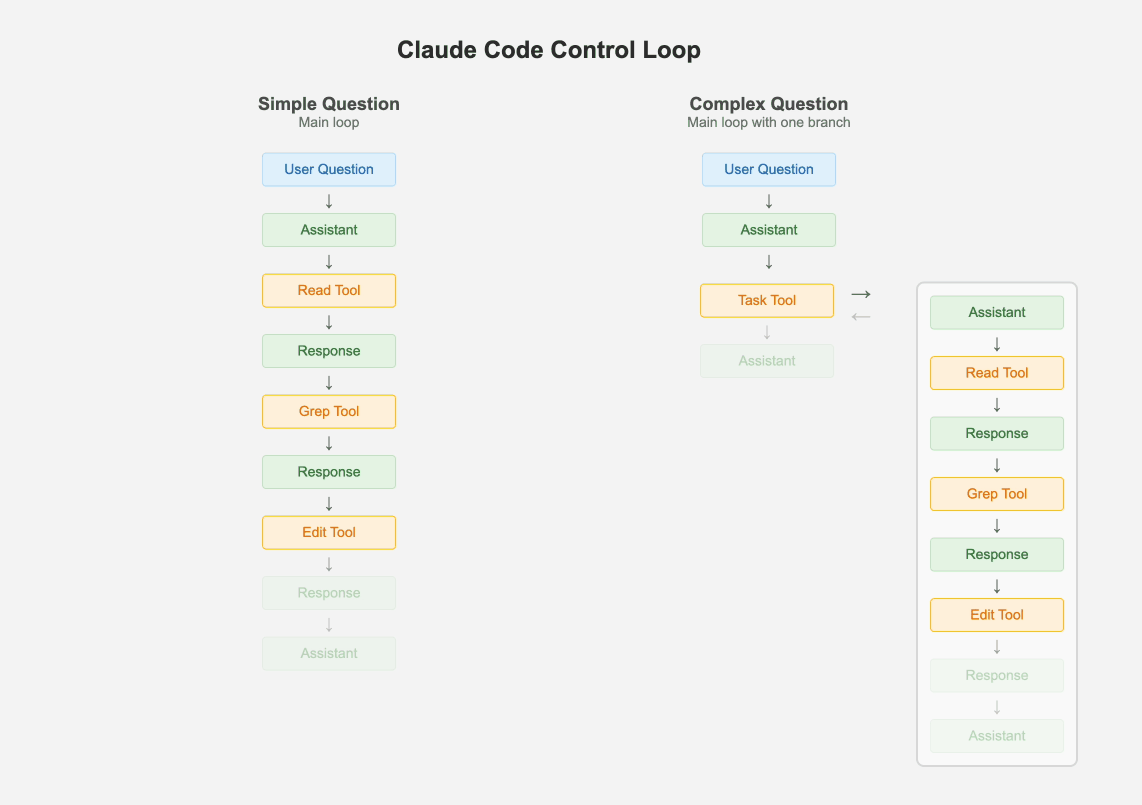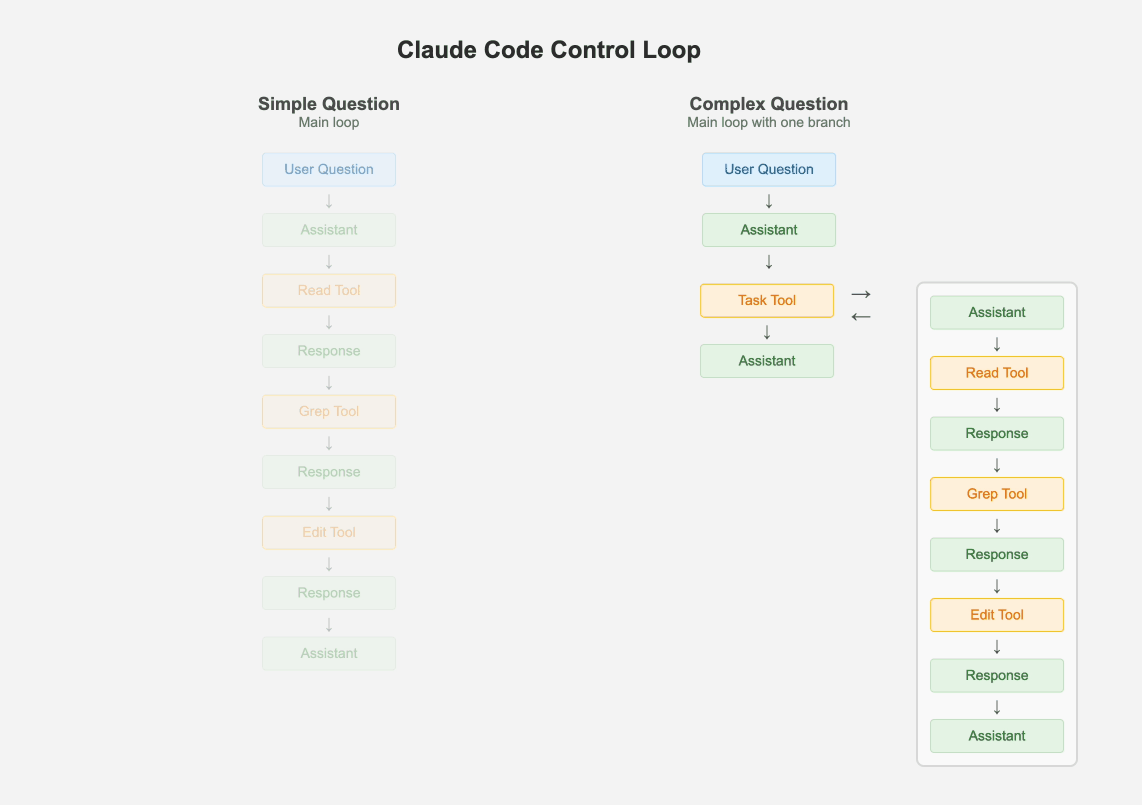
尽管多智能体系统风靡一时,Claude Code却只有一个主线程。它会周期性地使用几种不同类型的提示词来总结git历史、将消息历史压缩成一条消息,或者搞出一些有趣的UX元素。但除此之外,它只维护一个扁平的消息列表。它处理层级任务的一个有趣方式是,将自己作为子智能体派生出来,但这个子智能体不具备再派生更多子智能体的能力。最多只有一个分支,其结果会作为“工具响应”被添加到主消息历史中。
如果问题足够简单,主循环就通过迭代式地调用工具来处理。但如果有一个或多个复杂任务,主智能体就会创建自己的克隆体。这种“最多一个分支”和待办事项列表的结合,确保了智能体既有能力将问题分解为子问题,又能始终关注最终期望的结果。
我非常怀疑你的应用是否需要一个多智能体系统。每增加一层抽象,你的系统就更难调试,更重要的是,你偏离了通用模型改进的轨道。
1.2 大量使用一个更小的模型
CC发出的所有重要LLM调用中,超过50%是调用claude-3-5-haiku。它被用来读取大文件、解析网页、处理git历史和总结长对话。它甚至还被用来生成那个单词长度的处理标签——真的是响应每一次按键!这些小模型比标准模型(Sonnet 4, GPT-4.1)便宜70-80%。尽情地使用它们吧!
2. 提示词
Claude Code拥有极其详尽的提示词,里面充满了启发式规则、示例和重要(啧啧)提醒。其系统提示词长约2800个词元(token),而工具部分更是占据了惊人的9400个词元。用户提示词总是包含claude.md文件,这通常又会增加1000-2000个词元。系统提示词包含了关于语气、风格、主动性、任务管理、工具使用策略和执行任务等部分。它还包含了日期、当前工作目录、平台和操作系统信息以及最近的提交记录。
去读一下完整的提示词吧!
2.1 使用claude.md来协作处理用户上下文和偏好
大多数编程智能体开发者已经形成的一个主要模式是使用上下文文件(又名Cursor Rules / claude.md / agent.md)。Claude Code在有和没有claude.md的情况下,性能表现有天壤之别。对于开发者来说,这是一种传递无法从代码库中推断出的上下文,并固化所有严格偏好的绝佳方式。例如,你可以强制LLM跳过某些文件夹,或使用特定的库。CC在每次用户请求时都会发送claude.md的全部内容。
我们最近在MinusX中引入了minusx.md,它正迅速成为我们智能体用来固化用户和团队偏好的事实标准上下文文件。
2.2 特殊XML标签、Markdown和大量示例
使用XML标签和Markdown来结构化提示词已是公认的两种方式。CC广泛地同时使用了这两种。以下是Claude Code中一些值得注意的XML标签:
<system-reminder>: 用于在许多提示词部分的末尾提醒LLM那些它大概率会忘记的事情。例如:<system-reminder>这是一个提醒,你的待办事项列表当前为空。不要明确向用户提及此事,因为他们已经知道了。如果你正在处理的任务能从待办事项列表中受益,请使用TodoWrite工具创建一个。如果不需要,请忽略。再次强调,不要向用户提及此消息。</system-reminder><good-example>,<bad-example>: 用于固化启发式规则。当模型面临一个岔路口,有多条看似合理的路径/工具调用可供选择时,它们尤其有用。示例可以用来对比不同情况,并非常清楚地指明哪条路径是更可取的。例如:尽量在整个会话中通过使用绝对路径来维持当前工作目录,避免使用
cd。如果用户明确要求,你可以使用cd。1 2 3 4 5 6
<good-example> pytest /foo/bar/tests </good-example> <bad-example> cd /foo/bar && pytest tests </bad-example>
CC还使用markdown在系统提示词中划分清晰的章节。示例markdown标题包括:
- 语气和风格
- 主动性
- 遵循惯例
- 代码风格
- 任务管理
- 工具使用策略
- 执行任务
- 工具
3. 工具
去读一下完整的工具提示词吧——它长达惊人的9400个词元!
3.1 LLM搜索 >>> 基于RAG的搜索
CC与其他流行的编程智能体一个显著的区别在于它拒绝了RAG(检索增强生成)。Claude Code搜索你的代码库的方式和你一样,使用非常复杂的ripgrep、jq和find命令。由于LLM对代码理解得非常好,它可以使用复杂的正则表达式找到它认为相关的几乎任何代码块。有时它会用一个较小的模型来读取整个文件。
RAG理论上听起来是个好主意,但它引入了新的(更重要的是,隐藏的)失败模式。该用什么相似度函数?用什么重排器?如何对代码进行分块?如何处理大的JSON或日志文件?而使用LLM搜索,它只需查看JSON文件的前10行来理解其结构。如果需要,它可以再看10行——就像你做的那样。最重要的是,这是可以通过强化学习来学习的——这是那些大厂(BigLabs)已经在做的事情。模型完成了大部分繁重工作——理应如此,从而极大地减少了智能体中的活动部件数量。而且,将两个复杂的智能系统以这种方式连接起来实在太丑陋了。我最近和朋友开玩笑说,这是大模型时代的“摄像头 vs 激光雷达”之争,我只有一半是在开玩笑。
3.2 如何设计好工具?(低级工具 vs 高级工具)
这个问题让每个构建LLM智能体的人夜不能寐。你应该给模型通用的任务(比如有意义的动作),还是应该给它低级的任务(比如打字、点击和bash命令)?答案是:视情况而定(而且你应该两者都用)。
Claude Code拥有低级工具(Bash、Read、Write)、中级工具(Edit、Grep、Glob)和高级工具(Task、WebFetch、exit_plan_mode)。既然CC能用bash,为什么还要单独给一个Grep工具呢?这里的真正权衡在于,你期望智能体使用该工具的频率 vs 智能体使用该工具的准确性。CC使用grep和glob非常频繁,以至于将它们做成单独的工具是合理的,但同时,它也可以为特殊场景编写通用的bash命令。
类似地,还有更高级的工具,如WebFetch或mcp__ide__getDiagnostics,它们的功能是极其确定性的。这使LLM不必进行多次低级的点击和输入,从而保持在正轨上。帮帮这个可怜的模型,好吗!?工具描述中有详尽的提示词和大量示例。系统提示词中有关于“何时使用某个工具”或如何在两个可以完成相同任务的工具之间进行选择的信息。
Claude Code中的工具:
- Task, Bash, Glob, Grep, LS, ExitPlanMode, Read, Edit,
- MultiEdit, Write, NotebookEdit, WebFetch, TodoWrite, WebSearch, mcp__ide__getDiagnostics, mcp__ide__executeCode
3.3 让智能体管理一个待办事项列表
这样做是个好主意,原因有很多。“上下文退化”(Context rot)是长期运行的LLM智能体中的常见问题。它们开始时热情高涨地解决一个难题,但随着时间推移会迷失方向,最终产出垃圾。当前智能体设计有几种方式来解决这个问题。许多智能体尝试过明确的待办事项(一个模型生成待办事项,另一个模型执行它们)或多智能体交接+验证(产品经理智能体 -> 实现者智能体 -> QA智能体)。
我们已经知道,多智能体交接不是个好主意,原因有很多很多。CC使用一个明确的待办事项列表,但这个列表是由模型自己维护的。这让LLM保持在正轨上(它被重度提示要频繁参考待办事项列表),同时又给予模型在实现过程中途修正路线的灵活性。这也有效地利用了模型的交错思维能力,可以动态地拒绝或插入新的待办事项。
4. 可控性
4.1 语气和风格
CC明确地尝试控制智能体的美学行为。系统提示词中有关于语气、风格和主动性的章节——充满了指令和示例。这就是为什么Claude Code在注释和表现出的“热心”方面让人感觉很有“品味”。我建议直接将这部分的大段内容复制到你的应用中。
1
2
3
4
5
6
7
# 一些语气和风格的例子
- 重要:你不应该用不必要的开场白或结束语来回答(例如解释你的代码或总结你的行动),除非用户要求你这样做。
不要在用户未要求的情况下添加额外的代码解释摘要。
- 如果你不能或不愿意帮助用户做某事,请不要解释为什么或可能导致什么后果,因为这会让人觉得说教和烦人。
- 只有在用户明确要求时才使用表情符号。在所有交流中避免使用表情符号,除非被要求。
4.2 “这很重要” 仍然是业界顶尖水平
不幸的是,在要求模型不要做某事方面,CC也没什么高招。重要(IMPORTANT)、非常重要(VERY IMPORTANT)、**绝不(NEVER)和总是(ALWAYS)**似乎是引导模型避开雷区的最佳方式。我期望未来的模型会变得更具可控性,从而避免这种丑陋的做法。但就目前而言,CC大量使用了这种方法,你也应该这样做。一些例子:
1
2
3
- 重要:除非被要求,否则**不要添加任何**注释。
- 非常重要:你**必须**避免使用像`find`和`grep`这样的搜索命令。请改用Grep、Glob或Task进行搜索。你**必须**避免使用像`cat`、`head`、`tail`和`ls`这样的读取工具,而应使用Read和LS来读取文件。\\n - 如果你**仍然**需要运行`grep`,停下。**总是**先使用`rg`(ripgrep)。
- 重要:你**绝不能**为用户生成或猜测URL,除非你确信这些URL是用于帮助用户编程的。你可以使用用户在消息或本地文件中提供的URL。
4.3 编写算法(附带启发式规则和示例)
识别出LLM需要执行的最重要任务,并为其编写出算法,是极其重要的。试着角色扮演成LLM,演练一些例子,找出所有的决策点,并明确地把它们写下来。如果能以流程图的形式呈现会更有帮助。这有助于结构化决策过程,并辅助LLM遵循指令。一定要避免的是一大堆混乱的“该做”和“不该做”。它们更难追踪,也难以保持互斥。如果你的提示词长达几千个词元,你将不可避免地出现相互矛盾的“该做”和“不该做”。在这种情况下,LLM会变得极其脆弱,也无法融入新的用例。
Claude Code系统提示词中的任务管理、执行任务和工具使用策略等章节清晰地阐述了需要遵循的算法。这里也应该添加大量关于LLM可能遇到的各种场景的启发式规则和示例。
彩蛋:为什么要注意大厂的提示词?
在引导LLM方面,很多努力都是在试图逆向工程它们的后训练/RLHF数据分布。你应该用JSON还是XML?工具描述应该放在系统提示词里还是只放在工具里?你应用当前的状态信息呢?看看大厂在他们自己的应用里是怎么做的,并用它来指导你的设计,是很有帮助的。Claude Code的设计非常有主见,借鉴它来形成你自己的观点会很有益。
结论
再次强调,核心要点是保持简单。极端的脚手架框架弊大于利。Claude Code真的让我相信,一个“智能体”可以既简单又极其强大。我们已经将这些经验中的一部分融入了MinusX,并正在继续融入更多。
如果你对将自己的LLM智能体“Claude Code化”感兴趣,我很乐意与你聊聊——在Twitter上找我吧!如果你想为你的Metabase寻找类似Claude Code的可训练数据智能体,请查看MinusX或在这里和我安排一个演示。祝你(Claude式)编程愉快!
原文:What makes Claude Code so damn good (and how to recreate that magic in your agent)!?