《Effective AI Agent》条目 9:围绕KV缓存组织上下文降本提速
背景动机
很多团队把 Agent 的性能问题,归因到“模型慢 / 工具慢 / 网络慢”。但在生产里,最常见的真实元凶其实更朴素:你在重复喂同一段上下文,却每次都让模型从零开始做 Prefill。
Manus 的复盘把这事说得很直白:如果只能选一个指标,他们会选 KV-cache hit rate,因为它同时决定延迟与成本。Agent 的工作方式决定了它比聊天更“吃前缀”:每一步 tool call 都把 action+observation 追加进上下文,导致上下文越来越长,而输出(往往是结构化函数调用)相对很短;Manus 给出的平均输入输出 token 比例约 100:1。在这种形态下,Prefill 成本主导一切,KV 缓存命中就成了压舱石。
把它翻译成互联网架构的话就是:你在做一个“长请求、短响应”的系统。如果还不把缓存当回事,那就等于在高 QPS 下每次都绕过 CDN、绕过本地缓存、绕过 Redis——账单和延迟不爆才怪。
原理分析
先把“KV 缓存”讲清楚:LLM 推理一般分两段——
- Prefill(预填充):把输入 token 全跑一遍,构建注意力所需的 Key/Value(KV)中间结果。
- Decode(解码生成):逐 token 生成输出,复用之前的 KV。
如果两次请求的前缀 token 完全一致,那 Prefill 的那段 KV 是可以复用的。Manus 强调:只要前缀有一个 token 不同,缓存就会从那个位置开始失效,所以“前缀稳定性”是硬门槛。
这件事在工程上有三个直接推论:
1)KV 缓存的“命中”,本质是缓存键设计。 系统提示词、工具定义、序列化模板、甚至 JSON key 的顺序,都是缓存键的一部分。Manus 点名了一个非常常见的坑:把精确到秒的时间戳放在 system prompt 开头——功能上是“让模型知道现在时间”,工程上是“每次请求都换缓存键”。
2)上下文应当是 append-only 的日志,而不是可变对象。 Manus 的建议是“Make your context append-only”,避免回头去改历史 action/observation,并保证序列化确定性(例如 JSON key 顺序不稳定会“悄悄打爆缓存”)。 这跟互联网里“事件溯源 / WAL / 不可变日志”的价值一致:可重放、好对账、好观测、也更适合做快照与缓存。
3)缓存不是永生的,必须对齐 TTL 与路由策略。 以 OpenAI 的 Prompt Caching 为例:对足够长且有共同前缀的提示会自动命中缓存,并在返回 usage 中提供 cached_tokens 指标;同时缓存通常在一段时间不活跃后清理,并有最长保留上限。 这意味着你不仅要“写出可缓存的前缀”,还要用 session/sticky routing、断点(breakpoint)、重放策略去对齐“缓存会过期”这个现实。Manus 也提到:自建 vLLM 时要开启 prefix/prompt caching,并用 session IDs 让请求稳定路由到一致的 worker。
对 Agent 开发者的启发是:别把 KV cache 当黑盒——它会反过来决定你的编排形态能不能规模化。
工程实践
下面这些建议是“上下文工程”的一部分,但本质都属于缓存友好的系统设计——跟你做 API 网关、做序列化协议、做缓存穿透治理是一类事。
1)把上下文拆成“稳定前缀 + 追加日志”,并把稳定前缀当成契约
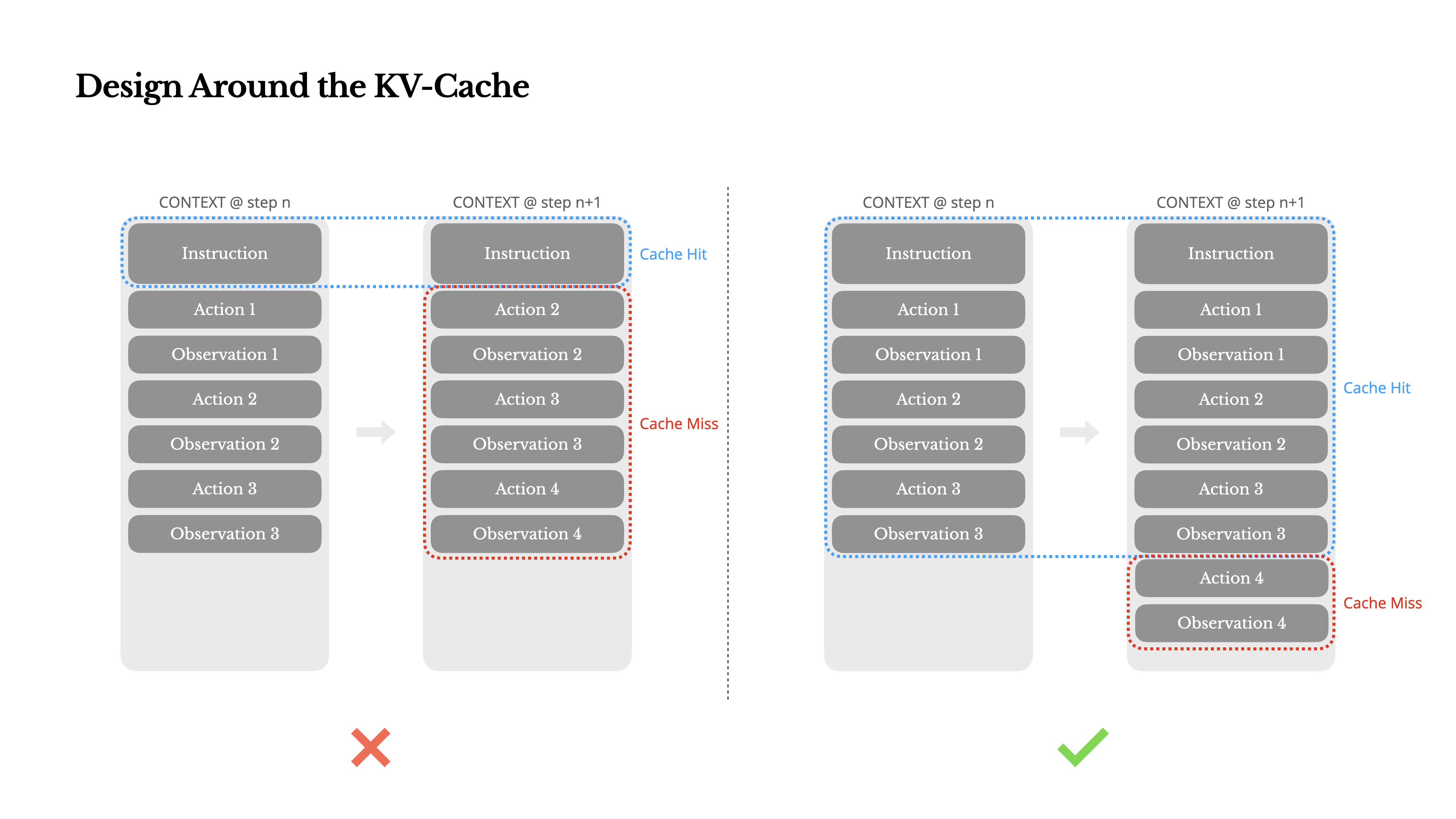
- 稳定前缀:system prompt、工具 schema、输出格式约束、少量固定示例(如果必须 few-shot)。
- 追加日志:每一步 action/observation、用户新输入、运行时状态摘要。 核心要求是:稳定前缀尽量长期不动;任何“动态内容”(时间、环境信息、A/B 版本号)都放到尾部,或者通过工具调用获得,而不是写进前缀开头。Manus 对此给了明确警示。
2)序列化必须“可预期”,否则缓存命中率会被细节暗杀
- JSON 一律 canonical:
sort_keys=True、固定分隔符、避免浮点格式抖动。 - 工具定义(schema)不要在运行时动态增删改;版本升级时走“灰度 + 双写 + 兼容期”,像你升级 protobuf 一样。 Manus 的经验是:上下文里任何非确定性都会悄悄让缓存从某个 token 开始失效。
3)工具集不要“动态改上下文”,优先“mask / constrain decoding” 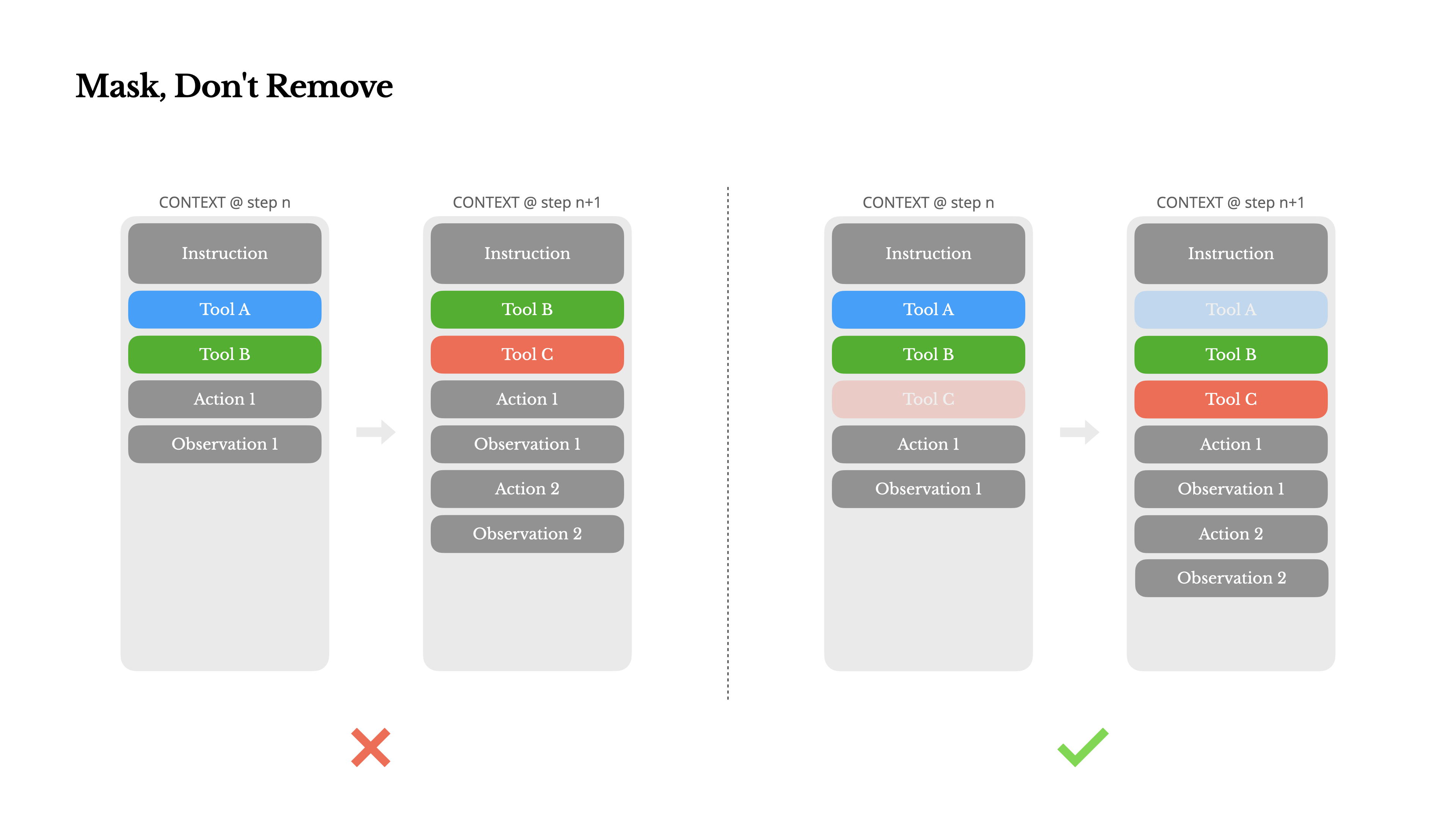 很多团队为了“让模型更聪明”,会每轮按需加载工具(RAG 式工具注入)。Manus 的结论相反:除非必要,不要在迭代中动态增删工具;因为工具定义通常在上下文前部,变一下就等于前缀全变,KV cache 直接归零。 更工程化的做法是:工具定义保持稳定,用状态机/策略在解码阶段约束可选动作(mask logits 或使用 provider 的 constrained function calling)。这跟“权限系统不改路由表,而是在鉴权层做决策”是同构的。
很多团队为了“让模型更聪明”,会每轮按需加载工具(RAG 式工具注入)。Manus 的结论相反:除非必要,不要在迭代中动态增删工具;因为工具定义通常在上下文前部,变一下就等于前缀全变,KV cache 直接归零。 更工程化的做法是:工具定义保持稳定,用状态机/策略在解码阶段约束可选动作(mask logits 或使用 provider 的 constrained function calling)。这跟“权限系统不改路由表,而是在鉴权层做决策”是同构的。
4)把缓存命中率纳入可观测与容量规划:它是性能 SLO 的上游指标 建议你至少把这些指标打到同一张看板上:
kv_cache_hit_rate(按请求、按会话、按 agent 类型)TTFT(time-to-first-token)prefill_tokens / decode_tokens比例- provider 返回的
cached_tokens从治理角度,它们的关系很像:缓存命中率下降 → TTFT 上升 → QPS 承载下降 → 成本上升。你会更容易定位“是某次 prompt 改版引入了时间戳 / schema 顺序变化 / 动态工具注入”。
5)接受缓存会过期:用“断点 + 重放”对齐 TTL
参考文献
- Yichao “Peak” Ji (Manus), Context Engineering for AI Agents: Lessons from Building Manus
https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus - OpenAI, Prompt Caching in the API
https://openai.com/index/api-prompt-caching/ - OpenAI, Prompt caching guide
https://platform.openai.com/docs/guides/prompt-caching - Anthropic, Contextual Retrieval in AI Systems
https://www.anthropic.com/news/contextual-retrieval - Woosuk Kwon et al., Efficient Memory Management for Large Language Model Serving with PagedAttention
https://arxiv.org/abs/2309.06180 - Ramya Prabhu et al., vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
https://arxiv.org/abs/2405.04437 - AWS, Amazon Bedrock announces preview of prompt caching
https://aws.amazon.com/about-aws/whats-new/2024/12/amazon-bedrock-preview-prompt-caching/