《Effective AI Agent》条目 10:文件是 Agent 最可靠的记忆载体,比“无限上下文”更有效
背景动机
很多团队说“Agent 没记忆”,其实是把两类完全不同的问题搅在一起了:一类是“我现在正在做什么”(工作记忆),另一类是“我长期知道什么/偏好什么”(长期记忆)。你不把它们拆开,工程上就会出现三种典型事故:要么上下文越滚越长、成本和延迟失控;要么为了省 token 乱压缩、结果关键细节丢了;要么任务跑到第 30 次 tool call 开始漂移,忘了最初目标。Manus 的复盘把这件事讲得很直白:Agent 的输入/输出 token 比例偏到 100:1,Prefill 成本主导,长链路里“记忆形态”比“模型聪明”更决定成败。
把它放回互联网架构语境,会更像我们熟悉的分层:工作记忆≈热数据/写多读多的缓存与日志数据;长期记忆≈稳定配置、知识库与可检索的状态仓库。关键不是“存不存”,而是“谁负责写、写到哪、什么时候读、以什么视图喂给模型”。
原理分析
工作记忆(Working Memory)解决的是“任务进行时的对齐问题”:目标、计划、进度、当前假设、下一步动作。它的特点是高频更新、强时效、强相关,应该尽量靠近执行Agent 上下文尾部(让模型注意力更容易看见)。
长期记忆(Long-term Memory)解决的是“跨会话的复用问题”:用户偏好、项目规范、常用命令、历史结论、稳定事实。它的特点是低频更新、可审计、可共享,不应该跟着每一步 tool call 被反复粘贴,而应该通过“检索/导入/引用”按需进入。
Google 的 ADK 把这件事抽象成一个很工程的说法:Context 不是字符串拼接,而是对更丰富状态系统的“编译视图”——Session/Memory/Artifacts 是“源”,processors 是“编译流水线”,每次调用 LLM 只拿“这一次的工作上下文”。这其实就是把“工作记忆 vs 长期记忆”在架构层面固化下来:存储和呈现分离。
工程实践
案例 1:Manus——用 todo.md 当工作记忆,用文件系统当“终极上下文”
Manus 的关键做法不是“更大窗口”,而是两刀切:
- 文件系统 = ultimate context:网页/文档等巨型 observation 不硬塞进 prompt,保留 URL/路径,让信息“可还原”,需要时再读文件/再抓取;这让压缩策略变得可逆,避免“不可逆压缩带来的信息丢失风险”。
- todo.md = 工作记忆 + 注意力操控:复杂任务里不断重写 todo 列表,把全局计划“背诵”到上下文末尾,抵抗 long context 的 lost-in-the-middle;他们甚至给了量化感:一个典型任务平均约 50 次 tool call,长链路漂移是常态风险。
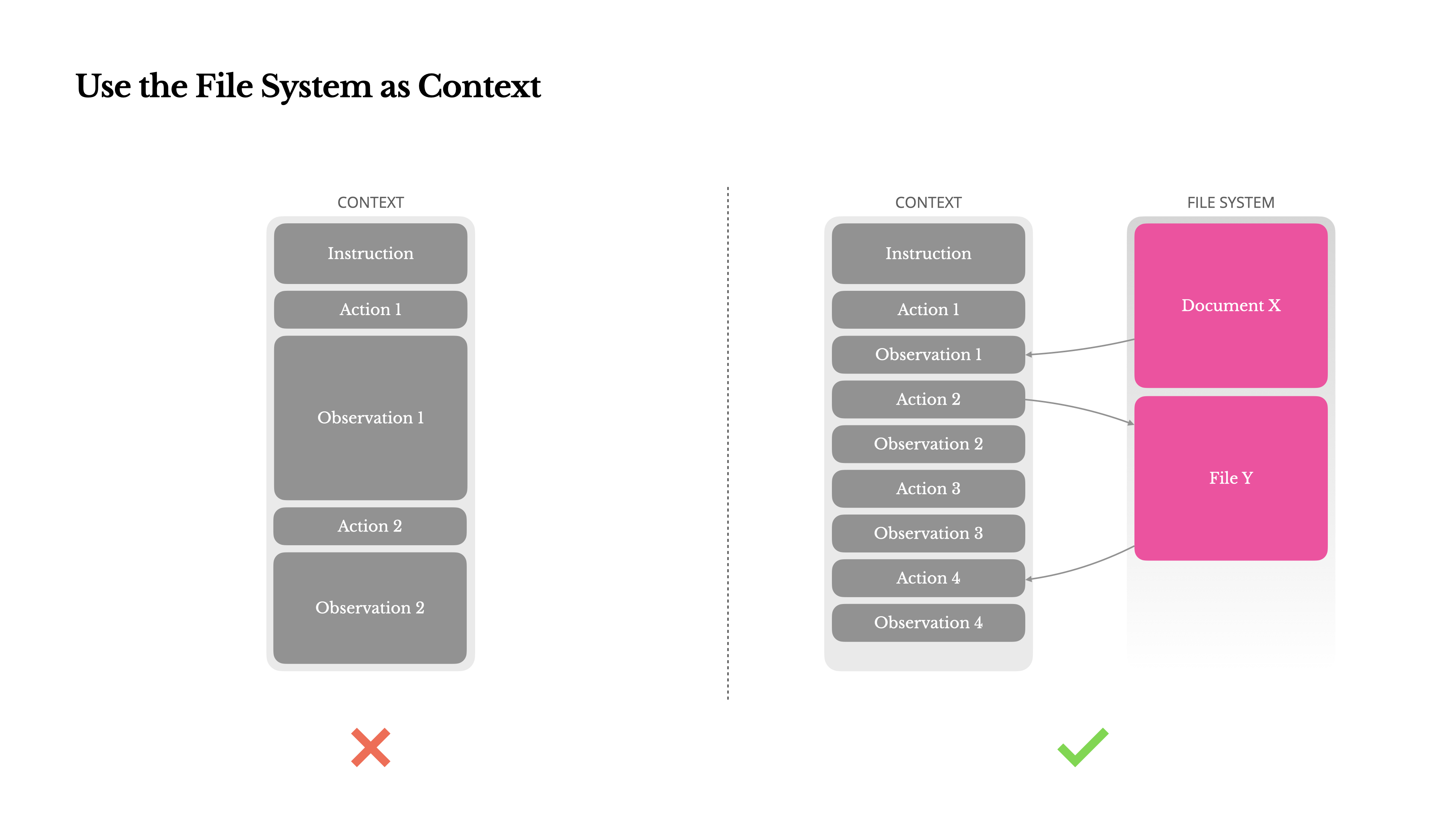
你可以把它理解成:todo.md 负责“我现在要干啥”,文件系统负责“我把东西放哪了,随时可取”。这就是工作记忆/长期记忆分治后带来的可控性。
案例 2:Claude Code——把记忆做成“可版本化的项目文件”,并且有清晰的优先级
Claude Code 的记忆不是“藏在黑盒里”,而是显式落在仓库与本机文件中:它定义了多层级的 CLAUDE.md(企业/项目/规则/用户/本地),启动时自动加载,高层优先、先加载,作为后续更具体规则的基础;CLAUDE.local.md 默认进 .gitignore,专门放“只对我生效”的项目偏好。
更工程的一点是:它会从当前目录向上递归查找相关记忆文件,并按需要在子树内发现并加载,这相当于把“记忆”做成了可组合、可继承、可审计的配置系统。
这类文件型长期记忆的价值在于:可 code review、可回滚、可共享——跟我们管理服务配置/架构约束是同一套治理逻辑。
案例 3:Letta——用“文件 + grep/search”在 LoCoMo 上跑出 74%:记忆更像“会不会查”而不是“存在哪”
Letta 的实验很“打脸式务实”:他们把对话历史直接放进文件,给 agent 文件工具(grep/search_files/open/close 等),在 GPT-4o mini 上用极少提示调优就拿到 74.0% LoCoMo。这说明在不少场景里,文件系统这种“模型天然会用的工具”反而更稳定,专用记忆工具的收益常常被“agent 是否会用”盖过去。 ([Letta][4])
这也给了一个工程启发:把长期记忆先落在最朴素、最可控的介质上(文件/文档/工单/README),再谈更复杂的知识图谱/向量库。否则你会花大量精力在“记忆系统很先进”,但 agent 用不好、评估也说不清。
案例 4:Mem0——把长期记忆做成两段式流水线:抽取→更新(ADD/UPDATE/DELETE/NOOP)
如果你的长期记忆目标是“跨会话用户偏好/事实沉淀”,那就需要比文件更结构化的写入策略。Mem0 给出的是典型的抽取 + 去重一致性更新:先从最新轮次、滚动摘要、最近 m 条消息里抽取候选记忆,再在更新阶段与相似条目比对,决定 ADD/UPDATE/DELETE/NOOP,以避免长期记忆变成“无限膨胀的垃圾堆”。
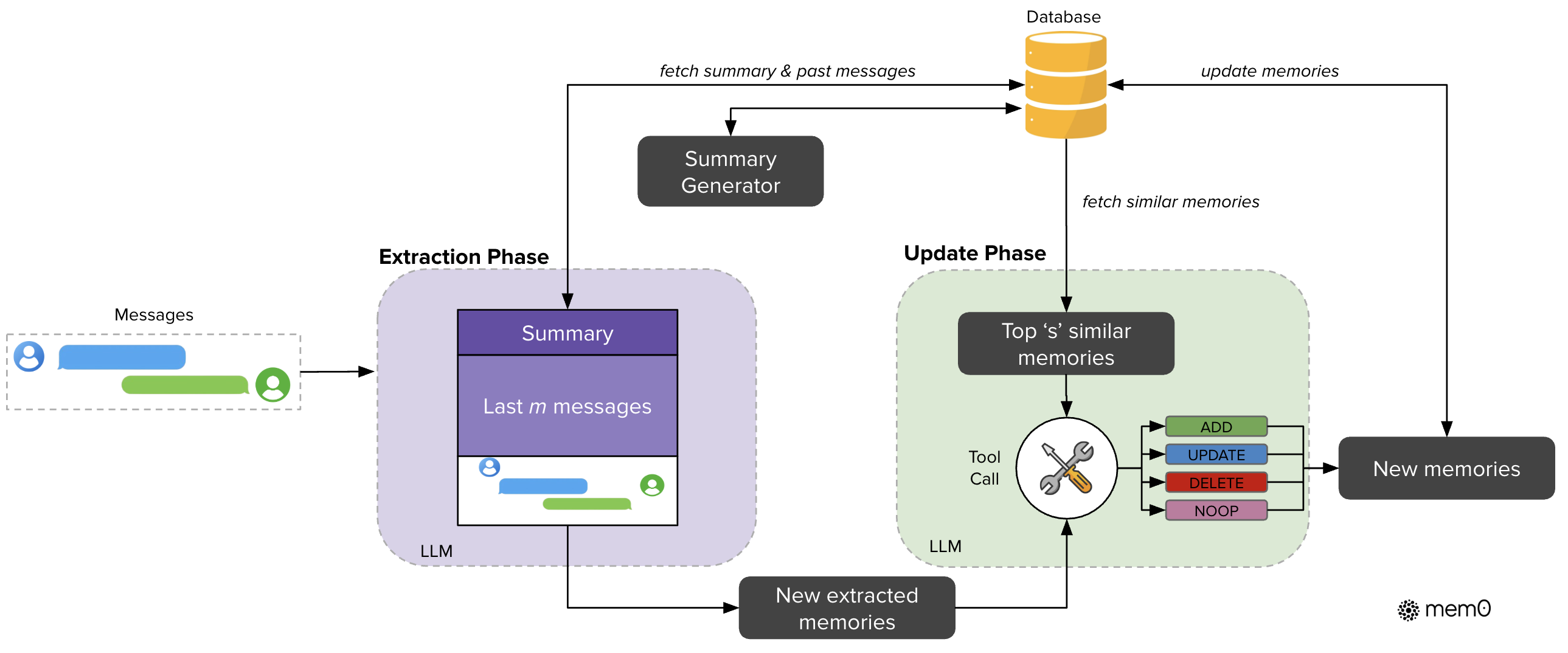
参考文献
- Manus — Context Engineering for AI Agents: Lessons from Building Manus
https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus - Letta — Benchmarking AI Agent Memory: Is a Filesystem All You Need?
https://www.letta.com/blog/benchmarking-ai-agent-memory - Google Developers Blog — Architecting efficient context-aware multi-agent framework for production (ADK)
https://developers.googleblog.com/architecting-efficient-context-aware-multi-agent-framework-for-production/ - Anthropic Claude Code Docs — *Manage Claude’s memory (CLAUDE.md hierarchy & lookup)
https://code.claude.com/docs/en/memory - Anthropic Engineering — Building effective agents
https://www.anthropic.com/engineering/building-effective-agents - Mem0 Research — Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
https://mem0.ai/research