《Effective AI Agent》条目 2:超越固定流程:用Agent解决开放性问题
背景动机
当任务的复杂度超过了预定义工作流的边界——例如“调研某行业的最新动态并写一份简报”,所需的工具调用顺序、搜索关键词和迭代次数在编码时无法预知——我们才需要引入 Agent。
然而,许多开发者常犯的错误是让 LLM “隐式思考”:直接把所有工具扔给模型,指望它一次性吐出最终结果。这种“黑盒”模式导致了著名的循环陷阱(Loop Trap):模型可能陷入无休止的搜索,或者在错误的方向上越跑越远。在生产环境中,不可见的思考过程意味着不可调试,不可控的循环意味着不可估量的 Token 成本。
原理分析
Agent 的核心架构可以想象成一个运行在“认知循环(Cognitive Loop)”上的状态机。
最经典的范式是 ReAct (Reasoning + Acting)。其核心原理是将大模型的“思考”过程解耦为两个明确的步骤:
- Reasoning(规划/思考):基于当前观测(Observation),决定下一步做什么。
- Acting(行动/执行):实际调用外部工具获取结果。
Andrew Ng 在《The Batch》中指出,Agentic Workflow 的威力往往不来自于更强的模型,而来自于迭代式的设计模式(Iterative Patterns)。比起单次 Zero-shot 尝试,让模型拥有“自我纠错”和“多步规划”的机会,能显著提升复杂任务的成功率。必须强制模型显式输出思维链(Chain of Thought),这不仅是 Prompt 技巧,更是架构层面的可观测性要求。
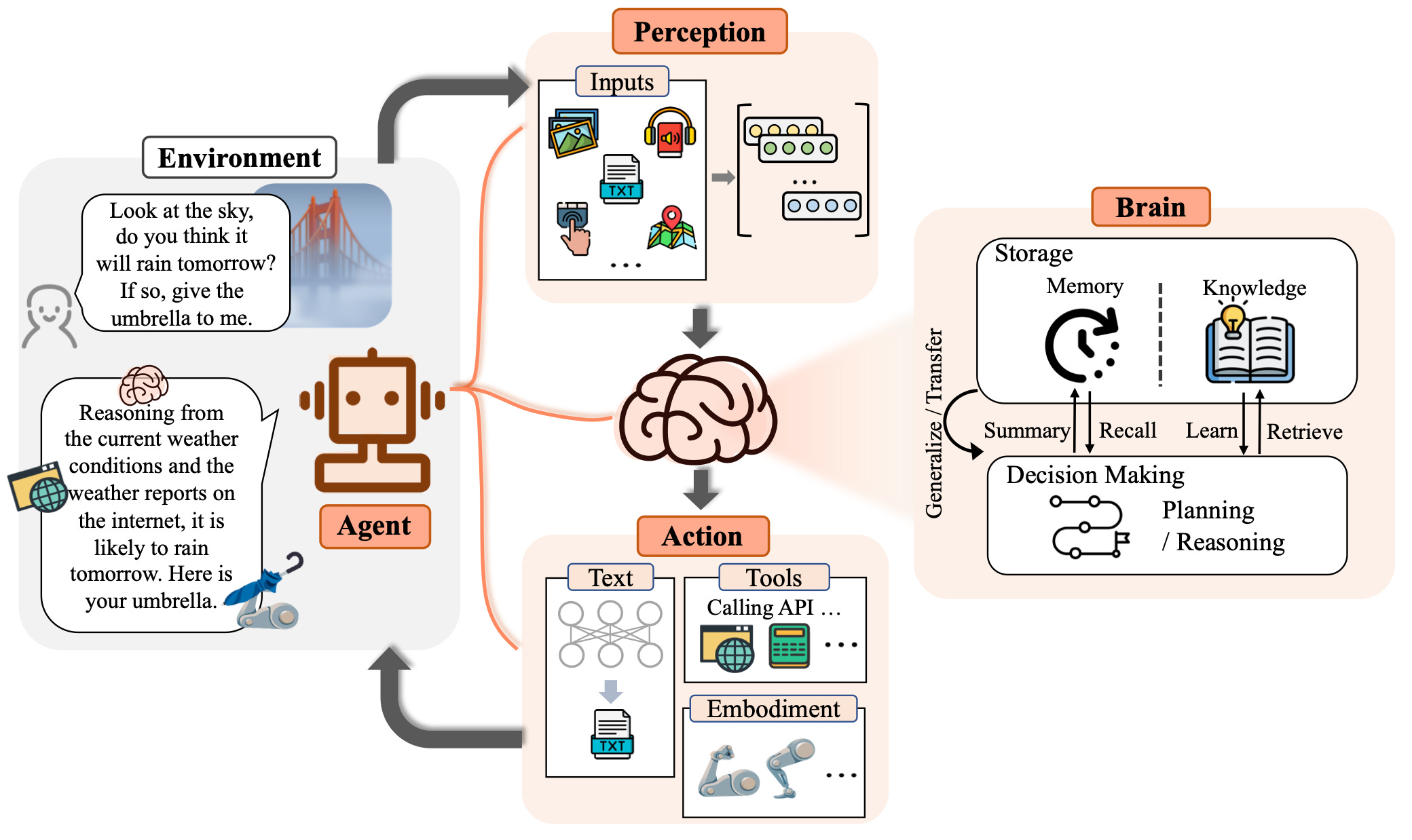
论文《The Rise and Potential of Large Language Model Based Agents: A Survey》阐述了 “大脑-感知-行动”的框架,系统地解释了如何将一个单纯的大语言模型(LLM)转变为一个具备自主能力的智能体(Agent)。LLM 充当控制中心(大脑),通过感知模块获取环境信息,利用工具和行动模块执行任务,从而实现从“被动问答”到“主动解决问题”的跨越。
Karpathy 在《Intro to Large Language Models》提出的 LLM OS 本质上是将大语言模型视为系统内核(CPU)的 Agent 架构,它通过调度内存、工具和感知模块来像计算机操作系统一样解决复杂问题,标志着 LLM 从单纯的“文本生成器”向“新型计算平台”的演进。
业界标杆案例
- Coding Agent:如Claude Code 和 Cursor。它们不仅仅是代码补全,而是构建了一个包含“终端反馈-代码修改-运行测试”的闭环。模型根据推理、规划、错误反馈、工具调用和测试验证解决了中小规模的编码问题,这是传统工作流无法实现的。
- Deep Research Agent:如OpenAI 和 Google的 Deep Research。它们通过“递归任务分解”处理开放性问题:Agent 自主生成搜索查询,阅读网页,发现新线索,再生成新的查询,直到收集足够信息。若用工作流去限定流程步骤(比如固定 3 次搜索 + 2 次总结),几乎注定要么信息不足,要么成本过高和结构不完整。
- Customer Support Agent:如Klarna 的客服 Agent。它自主处理了 2/3 的客户聊天(230 万次对话),其核心在于能够根据用户模糊的意图(如退货、查询物流、争议处理)在多个内部 API 系统中动态导航,而非遵循死板的 SOP 流程。
工程实践
设计 Agent 循环时,必须将其视为一个受限的有限状态机(FSM),而非无限递归的函数。
- 显式状态管理:摒弃散乱的变量,使用统一的 State 对象来持有历史对话、思考过程、工具调度、任务状态等全局状态。
- 硬性止损(Hard Guardrails):永远不要写
while True。必须在架构层设置max_iterations(最大迭代次数)和token_budget(Token 预算),在执行过程中执行死循环检测与启发式熔断。当达到限制时,强制中断并返回当前能得到的最佳结果,通过try-finally块确保资源释放。 - 分离系统指令:将“角色设定”与“动态任务”的上下文分离。在多轮循环中,系统提示词容易被过长的对话历史稀释,需要定期重申关键约束。
- 上下文工程:将 Context 视为稀缺的 RAM 资源。Agent 的成功依赖于精准的信息注入——既不能让无关的检索结果挤占推理空间,也不能让过早的历史噪音干扰当前的决策。
示例代码
不依赖复杂框架,用 Python 原生结构展示一个受控的 ReAct 循环骨架:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def run_agent_loop(agent, initial_state, max_steps=5):
state = initial_state
step_count = 0
while step_count < max_steps:
# 1. 显式推理:模型决定下一步行动
decision = agent.reason(state)
# 2. 终止判断:模型决定结束或达到硬性限制
if decision.action == "FINISH":
return decision.final_answer
# 3. 执行行动:调用工具
tool_result = execute_tool(decision.action, decision.params)
# 4. 状态更新:将“思考”(可选)与“观测”写入历史
state.append({
"role": "thought", # 记录思维链用于调试
"content": decision.reasoning
})
state.append({
"role": "observation", # 记录工具返回的客观事实
"content": tool_result
})
step_count += 1
return "Error: Agent exceeded maximum cognitive steps."
注:上面只是描述ReAct 循环的核心流程,在生产级环境中需结合更广泛的能力,如规划、记忆、容错处理和成本管控。
参考文献
- Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models (ICLR 2023) —
https://arxiv.org/abs/2210.03629 - Andrew Ng, The Batch: Agentic Design Patterns —
https://www.deeplearning.ai/the-batch/issue-242/ - Karpathy, Intro to Large Language Models(LLM OS) —
https://www.youtube.com/watch?v=zjkBMFhNj_g - Zhiheng Xi et al., The Rise and Potential of Large Language Model Based Agents: A Survey -
https://arxiv.org/pdf/2309.07864 - Anthropic, Building Effective Agents —
https://www.anthropic.com/research/building-effective-agents - LangChain, How to think about agent frameworks —
https://blog.langchain.com/how-to-think-about-agent-frameworks/ - Google ADK, State: The Session’s Scratchpad -
https://google.github.io/adk-docs/sessions/state/